Big Data Analytics: Types, Tools, and Enterprise Solutions
Understanding Big Data and Its Management
Every day, users generate 2.5 quintillion bytes of data. Statista predicts that by the end of 2021, the internet would generate 74 Zettabytes (74 trillion GBs) of data. Managing this vast and continuous data stream is increasingly difficult. Big data was introduced to manage such complex data, involving the extraction of large and complex datasets into meaningful information that traditional methods cannot analyze.
For example, Azure Cloud Services like Azure SQL and Azure Cosmos DB help in handling and managing sparsely varied kinds of data.
Data Types
Structured Data
Structured data can be defined as data residing in a fixed field within a record.
It is the type of data most familiar in our everyday lives, for example: birthday, address. A certain schema binds it, so all the data has the same set of properties. Structured data is also called relational data. It is split into multiple tables to enhance data integrity by creating a single record to depict an entity. Relationships are enforced by applying table constraints.
The business value of structured data lies within how well an organization can utilize its existing systems and processes for analysis purposes.
Semi-Structured Data
Semi-structured data is not bound by any rigid schema for data storage and handling. The data is not in the relational format and is not neatly organized into rows and columns like that in a spreadsheet. However, there are some features like key-value pairs that help in discerning the different entities from each other.
Since semi-structured data doesn’t need a structured query language, it is commonly called NoSQL data.
A data serialization language is used to exchange semi-structured data across systems that may even have varied underlying infrastructure.
Semi-structured content is often used to store metadata about a business process, but it can also include files containing machine instructions for computer programs.
This type of information typically comes from external sources such as social media platforms or other web-based data feeds.
Unstructured Data
Unstructured data is the kind of data that doesn’t adhere to any definite schema or set of rules. Its arrangement is unplanned and haphazard.
Photos, videos, text documents, and log files can be generally considered unstructured data. Even though the metadata accompanying an image or a video may be semi-structured, the actual data being dealt with is unstructured.
Additionally, unstructured data is also known as “dark data” because it cannot be analyzed without the proper software tools.
What is Hadoop?
The Apache project, Hadoop, provides a digital framework for distributed storage and processing of large datasets across system clusters using straightforward programming models with proper solutions. Hadoop was inspired by Google’s MapReduce and Google File System (GFS) papers to reduce the control system. Hadoop is an open-source platform for storing, processing, and analyzing enormous volumes of data across distributed computing clusters to process internal data. It is one of the leading technologies for big data processing and manipulating and has emerged as a vital tool for businesses working with internally used big data sets.
Characteristics of HDFS
The key attributes of HDFS are as follows:
Distributed Storage: Every data block that HDFS has divided into smaller pieces is stored in duplicate on a large number of nodes inside a Hadoop cluster. This distributed storage ensures fault tolerance and excellent data availability even if some nodes fail.
Scalability: Because HDFS is designed to scale horizontally, enterprises may easily add more nodes to their Hadoop clusters to accommodate increasing volumes of data.
Data Replication: To ensure the accuracy of the data, HDFS replicates data blocks between nodes. By default, each block is stored in three copies: two on the cluster’s other nodes and one on the node where the data is written.
Data Compression: HDFS supports data compression, which reduces the amount of storage required.
Four Main Components of Hadoop:
- HDFS (Hadoop Distributed File System)
- Storage layer of Hadoop
- Divides large files into blocks (default 128 MB or 256 MB) and distributes them across nodes
- Two main components:
- NameNode – Stores metadata (file names, block locations)
- DataNode – Stores actual data blocks
- Supports fault tolerance via replication
- Resource management layer of Hadoop
- Allocates system resources to applications
- Key components:
- ResourceManager – Manages global resources
- NodeManager – Manages individual node resources
- ApplicationMaster – Manages the life cycle of a specific application
- Processing engine of Hadoop
- Follows the Map → Shuffle → Reduce pattern
- Map: Filters and sorts data
- Reduce: Aggregates results
- Works in parallel across multiple nodes
- Set of shared Java libraries and APIs used by other Hadoop modules
- Provides essential services like:
- File I/O operations
- Serialization
- Logging
- Configuration
Data analytics is an important field that involves the process of collecting, processing, and interpreting data to uncover insights and help in making decisions. Data analytics is the practice of examining raw data to identify trends, draw conclusions, and extract meaningful information. This involves various techniques and tools to process and transform data into valuable insights that can be used for decision-making.
In this new digital world, data is being generated in an enormous amount which opens new paradigms. As we have high computing power and a large amount of data we can use this data to help us make data-driven decision making. The main benefits of data-driven decisions are that they are made up by observing past trends which have resulted in beneficial results.
In short, we can say that data analytics is the process of manipulating data to extract useful trends and hidden patterns that can help us derive valuable insights to make business predictions.
The Four Types of Big Data Analytics:
- Descriptive Analytics
- Focus: Summarizing historical data to understand past events and current trends.
- Purpose: Provides a foundational understanding of data’s historical context.
- Tools & Techniques: Data aggregation, data mining, data visualization.
- Example Use-case: Analyzing sales data over different periods to understand historical performance and identify trends in revenue or sales figures.
- Focus: Delving deeper into data to understand the root causes of specific outcomes or issues identified by Descriptive Analytics.
- Purpose: Uncovers the reasons behind observed trends and phenomena.
- Tools & Techniques: Drill-down analysis, data mining, data recovery, churn reason analysis, customer health score analysis.
- Example Use-case: An e-commerce company analyzes sales data showing a decrease in sales despite customers adding products to their carts. Diagnostic analytics helps identify potential reasons such as high shipping costs or limited payment options.
- Focus: Using historical data, statistical models, and machine learning to forecast future outcomes.
- Purpose: Anticipates future trends, risks, or opportunities.
- Tools & Techniques: Statistical modeling, machine learning, data mining.
- Example Use-case: An organization predicts employee turnover based on factors like tenure, performance scores, and engagement survey results, allowing for proactive intervention.
- Focus: Recommending actions based on the insights derived from Descriptive, Diagnostic, and Predictive Analytics.
- Purpose: Guides decision-making by suggesting optimal steps to achieve desired outcomes.
- Tools & Techniques: Optimization algorithms, simulation techniques.
- Example Use-case: Healthcare providers use prescriptive analytics to reduce readmission rates by recommending specific interventions based on patient data and risk factors.
IBM offers a comprehensive big data platform designed to help organizations of all sizes manage, analyze, and extract valuable insights from massive, diverse datasets. Their strategy involves leveraging open-source technologies, such as Apache Hadoop and Spark, and enhancing them with enterprise-grade features for security, governance, and ease of use.
IBM’s Big Data Platform is a comprehensive framework that integrates various tools and technologies to manage, process, and analyze big data efficiently.
It is designed to handle structured, semi-structured, and unstructured data for real-time decision-makin
Key Components
InfoSphere BigInsights: IBM’s enterprise-grade Hadoop distribution.
- Function: Manages and analyzes large amounts of structured and unstructured data in a reliable, fault-tolerant manner.
- Core: Based on Apache Hadoop and Spark, enhanced with IBM technologies for ease of use, analytics, and integration.
- Role: Augments existing analytic infrastructure, enabling firms to process high volumes of raw data and combine results with structured data.
InfoSphere Streams: A platform for processing streaming data in real-time.
- Function: Enables continuous analysis of massive volumes of streaming data with low latency.
- Core: Provides a runtime platform, programming model (Streams Processing Language – SPL), and tools for applications that process continuous data streams.
- Role: Addresses the challenge of analyzing large volumes of data in motion, especially for time-sensitive applications.
InfoSphere DataStage: A powerful data integration tool.
- Function: Moves and transforms data between operational, transactional, and analytical target systems.
- Core: Provides a graphical framework for developing data flow jobs (ETL/ELT) and includes features for parallel processing, enterprise connectivity, and data quality.
- Role: Streamlines data integration processes, allowing organizations to consolidate data from various sources and deliver it to target databases or applications.
Big SQL: A high-performance SQL engine for querying data stored in Hadoop.
- Function: Allows users with existing SQL skills to analyze large datasets in Hadoop without requiring complex programming.
- Core: Provides a robust engine for executing complex queries on both relational and Hadoop data.
- Role: Simplifies access and analysis of big data within the Hadoop ecosystem.
Use in Enterprise Solutions:
IBM’s big data platform and strategy were designed to address a wide range of enterprise needs:
- Customer-centric solutions: Analyzing customer data from various channels (social media, transactions, etc.) to understand sentiment, personalize offers, and improve customer service.
- Operational optimization: Analyzing sensor data, logs, and system performance metrics to improve efficiency, predict failures, and optimize resource allocation.
- Risk and financial management: Analyzing transactional data and real-time streams to detect fraud, monitor financial markets, and assess risk.
- Industry-specific solutions: IBM provided accelerators for specific industries, such as telecommunications and social data analytics, to speed up deployment and leverage industry-specific insights.
The Hadoop Distributed File System (HDFS)
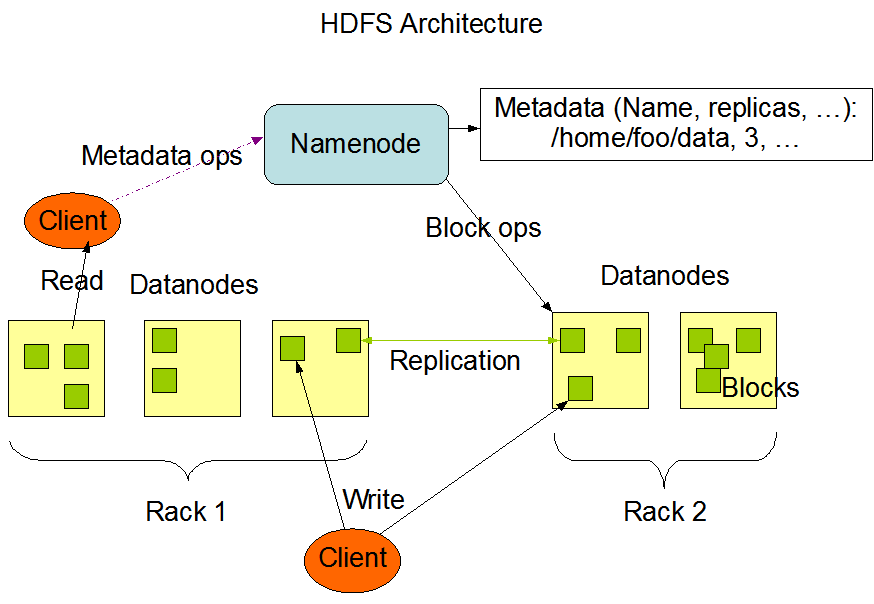
The Hadoop Distributed File System (HDFS) is a key component of the Apache Hadoop ecosystem, designed to store and manage large volumes of data across multiple machines in a distributed manner. It provides high-throughput access to data, making it suitable for applications that deal with large datasets, such as big data analytics, machine learning, and data warehousing. This article will delve into the architecture of HDFS, explaining its key components and mechanisms, and highlight the advantages it offers over traditional file systems.
HDFS Architecture:
NameNode (Master Node):
- Manages the filesystem namespace (directory structure, file permissions, etc.).
- Keeps track of where each file’s data blocks are stored across the DataNodes.
- Does not store the actual data itself, only the metadata.
- Responds to client requests for file operations (read, write, delete) and directs them to the appropriate DataNodes.
- Monitors the health of DataNodes through heartbeat messages.
DataNodes (Slave Nodes):
- Store the actual data blocks of files on their local disks.
- Handle read and write requests from clients as directed by the NameNode.
- Perform block creation, deletion, and replication upon instruction from the NameNode.
- Send block reports and heartbeats to the NameNode to report their status and the list of blocks they store.
Secondary NameNode:
- Acts as a helper to the NameNode, responsible for merging the EditLogs with the FsImage to create new checkpoints of the filesystem namespace.
- Helps reduce the NameNode’s workload and ensures that the filesystem metadata can be recovered in case of a failure.
HDFS Client:
- The interface through which users and applications interact with HDFS.
- Communicates with the NameNode to get metadata and then directly interacts with the DataNodes for reading and writing data.
Key Concepts in HDFS:
- Data Blocks: Files in HDFS are divided into fixed-size data blocks (typically 128 MB or 256 MB) for storage across DataNodes.
- Data Replication: HDFS replicates data blocks across multiple DataNodes (default replication factor is 3) to ensure data availability and fault tolerance.
- Fault Tolerance: Due to data replication and monitoring mechanisms, HDFS can recover from failures (like a DataNode crashing) without losing data.
- Data Locality: HDFS aims to move computation closer to the data (stored in DataNodes) to minimize network congestion and improve performance.
- Write-Once-Read-Many: HDFS is optimized for applications that write data once and read it multiple times.

Data Serialization (RDS) using R
Data serialization is the process of converting data structures or objects into a format that can be easily stored, transmitted, or reconstructed later. In R Programming Language one common method for data serialization is to use the RDS (R Data Serialization) format. The RDS format allows us to save R objects, such as data frames or models, to a file and later read them back into R.
Serialization: The process of converting complex data structures into an understandable format, suitable for storage and transmission is known as Serialization.
Significance of Data Seralization:
- Data Preservation: It’s necessary to keep your objects’ class properties and structure as it is while working with complex data structures in R. It is possible because serialization promises data’s integrity will not be compromised during deserialization, or “unpacking.”
- Data share: It’s normal for distinct applications or systems to need to share data. Data sharing between platforms is made simple by serialization, that gives a uniform format independent of computer language.
- Storage Efficiency: Data stored in human-readable text forms like CSV or JSON takes less space than data stored in serialization formats like RDS. When working with big datasets, it might be very crucial.
- Diminished Data Transfer Overhead: Data that has been serialized can cut down on the overhead that goes with translating data into and out of different formats via networks. The result of this is reduced resource use and quicker data transmission.
Basic Concepts in RDS
- RDS (R Data Serialization):
- RDS is a binary serialization format in R used to save R objects to a file.
- It allows you to save and load R objects while preserving their class, attributes, and structure.
- Serialization Functions:
- saveRDS() function in R is used to serialize an R object to a file.
- readRDS() function in R is used to deserialize and read the R object back into the R environment.
- Saving and Loading Data: Use saveRDS() to save R objects to a file, and readRDS() to load them back into R.
- Serialization of Different Data Types:
- RDS can serialize various data types, including vectors, lists, data frames, and more.
- It’s suitable for saving individual objects or entire datasets.
- Alternative Formats:
- Besides RDS, other serialization formats like CSV, JSON, and Feather may be used based on specific requirements.
- Choose the format that best fits the use case in terms of performance, interoperability, and storage size.
- Compressing Serialized Data: For large datasets, consider compressing serialized data to reduce file size. RDS supports compression using the “gzip” or “xz” compression algorithms.
MapReduce Framework
Map Reduce is a framework in which we can write applications to run huge amount of data in parallel and in large cluster of commodity hardware in a reliable manner.
Phases of MapReduce
MapReduce model has three major and one optional phase.
- Mapping
- Shuffling and Sorting
- Reducing
- Combining
- Mapping
It is the first phase of MapReduce programming. Mapping Phase accepts key-value pairs as input as (k, v), where the key represents the Key address of each record and the value represents the entire record content.The output of the Mapping phase will also be in the key-value format (k’, v’).
- Shuffling and Sorting
The output of various mapping parts (k’, v’), then goes into Shuffling and Sorting phase. All the same values are deleted, and different values are grouped together based on same keys. The output of the Shuffling and Sorting phase will be key-value pairs again as key and array of values (k, v[ ]).
- Reducer
The output of the Shuffling and Sorting phase (k, v[]) will be the input of the Reducer phase. In this phase reducer function’s logic is executed and all the values are Collected against their corresponding keys. Reducer stabilize outputs of various mappers and computes the final output.
- Combining
It is an optional phase in the MapReduce phases . The combiner phase is used to optimize the performance of MapReduce phases. This phase makes the Shuffling and Sorting phase work even quicker by enabling additional performance features in MapReduce phases.
Types of MapReduce Functions:
- Map Function
- Proceses input data and converts it into key-value pairs.
- Example: Splits a line of text into words.
- Reduce Function
- Aggregates the values based on keys from the Map output.
- Example: Counts occurrences of each word.
- Task Failures: Individual Map or Reduce tasks might fail due to errors in user code, hardware issues, or resource exhaustion.
- Application Failures: Entire MapReduce jobs can fail due to misconfigurations, logical errors, or insufficient resources.
- Master/Coordinator Failures (e.g., JobTracker or Resource Manager): If the master component responsible for managing and coordinating the job fails, it can disrupt the entire job execution.
- Node Failures (e.g., TaskTracker or Node Manager): A node responsible for executing tasks can fail, causing the tasks running on it to fail as well.
Handling MapReduce Job Failures
MapReduce frameworks, such as Hadoop, have built-in mechanisms to handle failures and ensure job completion:
- Task Retries: When a task fails, the framework automatically reschedules and retries it on a different node. The maximum number of retries is configurable.
- Task Isolation: If a node consistently fails tasks, the framework isolates it and avoids scheduling further tasks on that node.
- Speculative Execution: If a task runs slower than expected (a “straggler”), the framework can launch a duplicate task on a different node. The result from the first task to finish is used, improving overall job performance.
- Handling Master Failure: In systems like YARN, which improve upon classic MapReduce, single points of failure like the JobTracker are addressed. If a master fails, the job can be re-submitted or restarted.
- Handling Node Failure: If a node running map tasks fails, the MapReduce framework can reschedule those map tasks. For reduce tasks, the framework handles the loss of intermediate data from failed nodes.
- Custom Error Handling: Developers can implement specific error handling within their Map or Reduce functions to manage expected errors and ensure data consistency.
MapReduce Job Scheduling Strategies
Job scheduling in MapReduce involves managing and allocating resources to multiple jobs submitted by users in a shared cluster environment. The goal is to efficiently utilize cluster resources, prioritize jobs, and ensure fairness.
Here are the common job scheduling strategies used in MapReduce:
- FIFO Scheduler (First-In-First-Out): The default scheduler in Hadoop, which processes jobs in the order they are submitted to the queue. This is a simple approach but can lead to long waiting times for shorter jobs if a large job is at the front of the queue.
- Capacity Scheduler: This scheduler enables multiple organizations or users to share a cluster and allocate a dedicated portion of cluster resources to each.
- It uses a hierarchical queue structure to represent the organizations and groups that utilize the cluster resources.
- It provides capacity assurance and resource guarantees to each organization or queue.
- Fair Scheduler: This scheduler aims to provide an equal share of cluster resources to all running applications over time.
- It allows the configuration of pools of resources, with guaranteed minimum shares for each pool.
- It can preemptively kill tasks in pools running over capacity to provide resources to pools running below capacity.
- Pig Latin
Purpose: Pig Latin is a data flow language used to write data analysis programs. It simplifies the creation of MapReduce jobs by providing a higher-level abstraction over the data processing flow. It’s particularly well-suited for ETL (Extract, Transform, Load) tasks and processing both structured and semi-structured data.
Key Features:
- Procedural Language: Pig Latin statements describe a series of operations to be applied to the data, defining a data processing pipeline.
- Nested Data Model: Supports complex data types like tuples, bags, and maps, allowing for more natural representation and processing of data with nested structures.
- Operators: Provides a rich set of operators for data manipulation, including loading, storing, filtering, grouping, joining, and transforming data.
- Hive
Purpose: Apache Hive is a data warehousing system built on top of Hadoop, designed for querying and managing large distributed datasets. It provides an SQL-like interface called HiveQL, making it easy for data analysts familiar with SQL to interact with big data stored in HDFS.
Key Features:
- Data Warehouse System: Provides features for data summarization, querying, and analysis.
- SQL-Like Interface (HiveQL): Allows users to write queries using a language very similar to SQL, simplifying big data processing for those with SQL experience.
- Metadata Storage: Uses a metastore to store schema and metadata about the tables and data, enabling structured queries over unstructured data.
- HiveQL (Hive Query Language)
Purpose: HiveQL is the query language used in Hive. It provides a SQL-like interface for interacting with and managing data stored in Hive tables.
Key Features:
- SQL-like Syntax: Familiar to SQL users, offering a high-level abstraction over Hadoop complexities.
- DDL and DML Support: Supports Data Definition Language (DDL) for creating and managing tables, and Data Manipulation Language (DML) for querying and modifying data.
- Data Loading: Provides commands for loading data into tables from various sources.
4. When to Use Which Tool:
- Choose Pig when:
- You need to perform complex data transformations and ETL tasks.
- You’re working with semi-structured or unstructured data.
- You are a programmer or researcher who prefers a procedural scripting approach.
- You require fine-grained control over the data processing flow.
- Choose Hive when:
- You are a data analyst who is comfortable with SQL.
- You need to perform ad-hoc queries and generate reports from structured data.
- You are building a data warehouse on top of Hadoop.
- You require integration with BI tools and reporting applications.

Apache Kafka
Apache Kafka is a distributed streaming platform designed for building real-time data pipelines and streaming applications. It handles large volumes of data with high throughput and low latency, making it ideal for event-driven architectures and real-time processing needs. Kafka was originally developed at LinkedIn and later open-sourced, and it’s now widely used across various industries.
Kafka’s core capabilities include:
- Publishing and subscribing to streams of records: Producers write data to topics, and consumers read from them.
- Storing streams of records: Kafka durably stores event streams in the order they were generated, allowing for later retrieval and analysis.
- Processing streams of records in real-time: Kafka enables processing data as it arrives, facilitating real-time analytics and event-driven applications.
Kafka Architecture Components:
Kafka’s architecture consists of several key components:
- Kafka Cluster: A group of Kafka brokers working together.
- Brokers: Servers that handle data, each with a unique ID and hosting partitions. One broker is the controller, managing the cluster.
- Topics: Categories for data streams where producers publish and consumers subscribe.
- Partitions: Topics are divided into partitions, which are ordered, immutable logs of events, enabling parallel processing.
- Producers: Applications that write events to topics, distributing them across partitions.
- Consumers: Applications that read data from topics, tracking their progress with offsets.
- ZooKeeper/KRaft: Historically, ZooKeeper managed the cluster. Newer Kafka versions use KRaft for metadata management.
- Offsets: Identifiers for messages within a partition, used by consumers to track progress.
- Consumer Groups: Groups of consumers sharing the load of processing data from a topic.
Kafka APIs:
Kafka offers various APIs for interactions:
- Producer API: For publishing records.
- Consumer API: For subscribing and processing records.
- Streams API: A library for real-time data processing.
- Connector API: For integrating with external systems.
- Admin API: For managing Kafka objects.
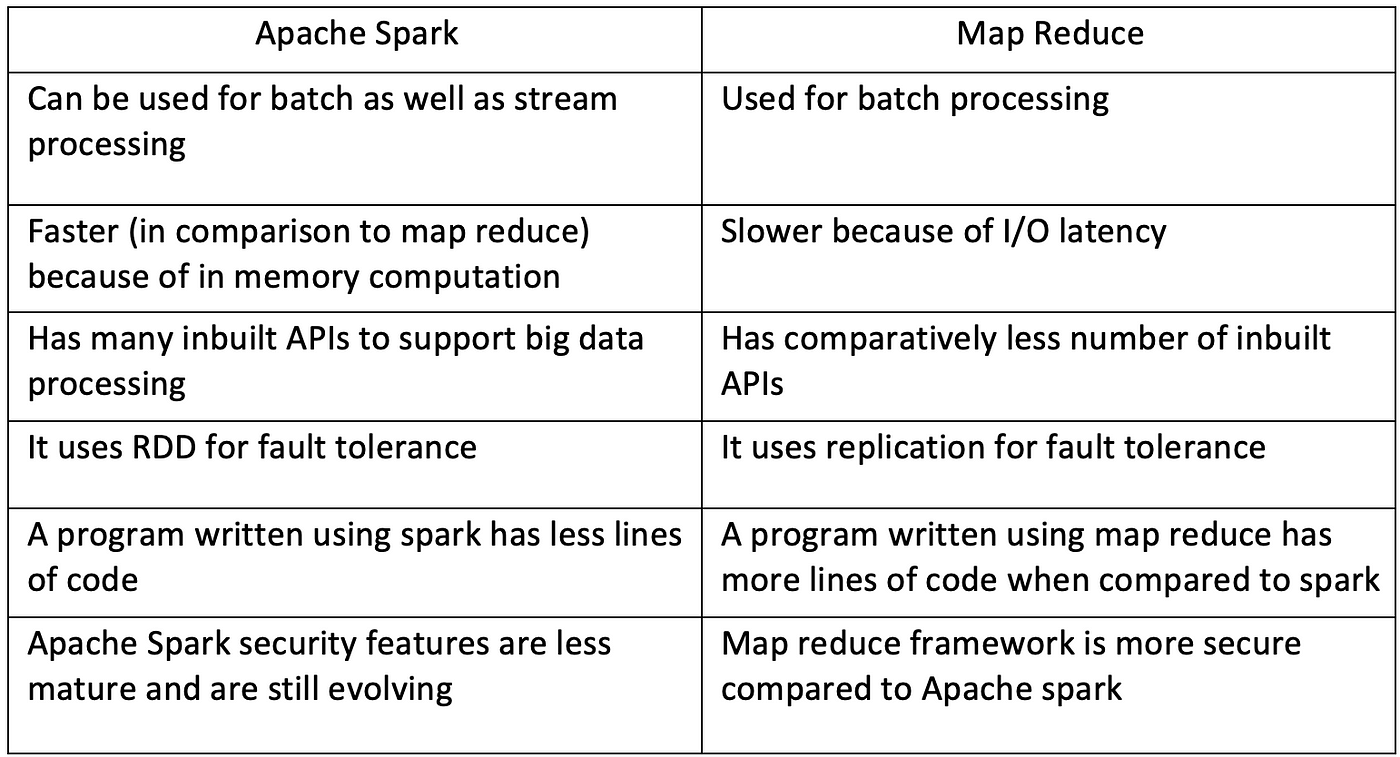
Limitations of MapReduce:
- Disk-Based Processing: MapReduce processes data primarily on disk, reading and writing intermediate results to the Hadoop Distributed File System (HDFS) after each Map and Reduce stage. This reliance on disk I/O introduces significant latency, especially for iterative algorithms common in machine learning.
- Sequential Multi-Step Jobs: MapReduce jobs involve a fixed sequence of Map and Reduce phases, where each step requires data to be written to and read from disk. This rigidity limits its performance for iterative or multi-stage computations, as the output of one job must be stored before the next can begin.
- Difficulty for Iterative Tasks: Iterative algorithms, like those used in machine learning or graph processing, require repeated access to the same dataset. MapReduce’s disk-based approach makes these iterative computations slow and inefficient.
- Limited Interactivity: MapReduce is primarily a batch processing framework, making it less suitable for interactive data analysis and querying.
- Programming Complexity: Developing MapReduce applications often requires writing verbose code in Java, which can be challenging for developers.
How Spark and RDDs Address MapReduce Limitations:
Apache Spark tackles these challenges by introducing the Resilient Distributed Dataset (RDD) and focusing on in-memory computation:
- In-Memory Processing: Instead of relying solely on disk, Spark can load and process data in RAM, significantly reducing disk I/O and accelerating computation speeds. This is particularly beneficial for iterative algorithms that repeatedly access the same dataset.
- Resilient Distributed Datasets (RDDs): RDDs are the fundamental data structure in Spark, representing immutable, fault-tolerant collections of data distributed across a cluster. RDDs are designed to efficiently handle transformations and actions in parallel across multiple nodes.
- Lazy Evaluation: Spark utilizes lazy evaluation, meaning transformations on RDDs are not executed immediately but rather recorded in a logical execution plan called a Directed Acyclic Graph (DAG). This allows Spark to optimize the entire workflow before execution, reducing unnecessary computations and data shuffling.
- Fault Tolerance through Lineage: RDDs achieve fault tolerance by keeping track of the lineage of transformations applied to the data. If a partition is lost due to a node failure, Spark can recompute it by following the lineage from the original data source.
- Optimized Execution with DAGs: Spark’s DAG execution model enables the optimization of the execution plan, allowing for pipelining of operations and reducing data shuffling. This contrasts with MapReduce’s rigid two-stage approach and leads to more efficient task execution.
- Caching and Persistence: Spark allows users to persist intermediate data in memory or on disk for reuse across multiple operations. This caching mechanism boosts performance, particularly for iterative algorithms and interactive data analysis.
- Unified Platform: Spark offers a unified platform for handling diverse workloads, including batch processing, real-time streaming, machine learning (with MLlib), graph processing (with GraphX), and SQL-based querying (with Spark SQL). This eliminates the need for separate tools and simplifies data pipelines.
- Ease of Use and Multi-Language Support: Spark provides high-level APIs in languages like Scala, Java, Python, and R, making development easier and more accessible. Developers can focus on application logic rather than manual parallelization and fault recovery.
Apache Pig
Apache Pig is a high-level data flow scripting platform designed for analyzing large datasets stored within the Apache Hadoop framework. It simplifies the process of creating and executing MapReduce jobs, especially for users who aren’t deeply familiar with Java programming.
Key Aspects of Apache Pig:
- Pig Latin: Pig uses a high-level scripting language called Pig Latin. This language offers a more user-friendly, SQL-like syntax for expressing data transformations, aggregations, and analysis tasks. Compared to writing complex Java-based MapReduce code, Pig Latin requires significantly fewer lines of code, making it easier to manage and develop solutions.
- Abstraction over MapReduce: Apache Pig serves as an abstraction layer over MapReduce, hiding the complexities of the underlying framework. It automatically translates Pig Latin scripts into MapReduce jobs, allowing users to focus on data processing logic rather than low-level implementation details.
- Handling Diverse Data: Pig is versatile and can handle various data types, including structured, semi-structured, and unstructured data. This makes it suitable for processing diverse data sources like log files, text data, and data from social media feeds.
Applications of Apache Pig
Apache Pig is widely used in various applications within the big data ecosystem:
- ETL (Extract, Transform, Load) Processes: Pig is commonly used for ETL tasks, enabling organizations to extract data from multiple sources, transform it into the desired format (e.g., cleaning, filtering, structuring), and load it into HDFS or other storage systems.
- Log Analysis: Pig is effective for analyzing large volumes of log data (web logs, application logs, etc.) stored in HDFS. It simplifies the process of parsing, processing, and analyzing these logs to extract valuable insights.
- Data Warehousing and Analytics: Pig is utilized in data warehousing and analytics workflows to quickly process and transform large datasets. It supports aggregations, joins, and other data manipulation tasks to derive insights for business intelligence.
- Data Transformation: Pig facilitates data transformation by simplifying the process of cleaning, filtering, and structuring data to improve its quality for downstream analysis.
- Iterative Processing: Pig supports iterative data processing, making it suitable for tasks like machine learning and graph processing that involve multiple passes through the data.
- Text Processing: Pig’s capabilities extend to processing large amounts of text data, including features for text parsing, tokenization, and analytics, which are useful for sentiment analysis and natural language processing.
Data Serialization
Data serialization is the process of converting complex data structures or objects (like those you might use in programming, including arrays, lists, or custom object instances) into a byte stream. This byte stream is a sequential series of bytes that represents the data in a format suitable for storage or transmission.
Think of it like this: when you have an object in your program’s memory, it’s organized in a way that the program understands. But if you want to store that object in a file or send it across a network, you need a standard way to represent its data so that another program, potentially
running on a different system or using a different language, can read and understand it.
Data serialization makes data portable and persistent, enabling you to save the state of an object and reconstruct it later, either in the same program or a different one.
The reverse process, reconstructing the original data structure from the byte stream, is called deserialization.
How the Type of Data Affects Data Serialization
Structured Data: This data has a predefined format and schema, fitting neatly into tables with rows and columns, like data in a relational database or a spreadsheet. Serialization of structured data can leverage formats like CSV or specialized binary formats like Parquet, which are optimized for tabular data and allow for schema-based processing and querying. These formats can efficiently store and process structured data in a columnar fashion, leading to better query performance and reduced storage space.
Unstructured Data: This type of data lacks a predefined format or schema and can include text documents, images, audio, or video files. Serializing unstructured data requires formats that can handle the raw data’s flexibility, and potentially incorporate metadata to add structure where needed. For instance, serializing multimedia files might involve using formats like JPEG, MP3, or MPEG, which are specific serialization formats designed for these data types. Advanced binary formats like Apache Avro or Protocol Buffers can be used to handle complex unstructured data, and their schemas can be defined using JSON.
Complex Data Structures: Data with nested structures, arrays, and other complex data types can be challenging to serialize efficiently. Traditional formats might struggle, leading to increased storage requirements and slower processing. Formats like Apache Avro, Parquet, and ORC are designed to handle complex data structures in a distributed environment like Hadoop. Avro provides schema evolution capabilities and a compact binary format. Parquet and ORC offer column-oriented storage, which enhances query performance and reduces storage space.
Primitive Data Types: Simple data types like numbers and strings can be serialized in various formats, such as JSON or binary formats. The choice often depends on the need for human readability and performance requirements. Binary formats are generally more space-efficient and faster for serializing primitive data types compared to text-based formats.
Time-Series Data: This data is often generated at high frequency and requires efficient serialization for high-performance ingestion and minimal storage overhead. Serialization formats that optimize for time-series data, considering the need for data integrity and performance, are crucial in such scenarios.
Kerberos is a network authentication protocol that plays a crucial role in securing Hadoop clusters by providing a robust way to verify the identity of users and services. In essence, it uses a ticket-based system to allow nodes communicating over a non-secure network to prove their identities to each other securely.
1. Core Components:
Key Distribution Center (KDC): This is the central server and trusted third party that manages the entire Kerberos authentication process. It’s often referred to as a domain controller in Windows environments. The KDC is typically composed of three key elements:
Kerberos Database: Stores information about all users and services (known as principals) within the Kerberos realm, including their associated secret keys (passwords).
Authentication Server (AS): Performs the initial authentication of users and services. When a client requests access, the AS verifies their credentials against the database and, if successful, issues a Ticket-Granting Ticket (TGT).
Ticket-Granting Server (TGS): Issues service tickets to authenticated users (those possessing a valid TGT) that grant them access to specific Hadoop services.
Principals: Every user or service in Hadoop that interacts with Kerberos is represented by a unique identity called a principal.
User Principals: Represent human users who need to access the cluster (e.g., user@REALM).
Service Principals: Represent Hadoop services running on specific hosts (e.g., hdfs/hostname.fqdn.example.com@YOUR-REALM.COM).
Realms: A Kerberos realm is an administrative domain that defines a group of principals tied to the same KDC. Realms establish boundaries for administration and can have their own configuration settings.
Keytabs: A keytab is a file containing the principal and its encrypted secret key. Keytabs allow services or users to authenticate without needing to interactively enter a password.
Delegation Tokens: Hadoop employs delegation tokens to handle job authentication at execution time, especially for long-running jobs. A delegation token is a secret key shared between a user and a NameNode, allowing the user to authenticate once and pass credentials to all tasks of a job without overwhelming the KDC with repeated authentication requests.
2. Authentication Flow:
The Kerberos authentication process in Hadoop typically follows these steps:
Initial Client Authentication: A user or service (principal) requests authentication from the KDC’s Authentication Server (AS).
AS Verification: The AS verifies the principal’s credentials (e.g., password or keytab) against the Kerberos database.
TGT Issuance: If authentication is successful, the AS issues a Ticket-Granting Ticket (TGT) to the principal. The TGT is essentially proof that the client has been authenticated and is stored in a credentials cache.
Service Ticket Request: When the principal needs to access a specific Hadoop service (e.g., HDFS), it requests a service ticket from the KDC’s Ticket-Granting Server (TGS) using its TGT.
TGS Verification and Service Ticket Issuance: The TGS validates the TGT and, if valid, issues a service ticket to the principal. This ticket grants access to the requested service for a limited time.
Application Server Request: The principal uses the service ticket to authenticate with the application server hosting the requested service.
Application Server Authentication: The application server verifies the service ticket and, if valid, authenticates the principal and allows access to the requested resource.